
Intro
The terrific guys at informática64 put together the FOCA tool (for mostly automated metadata extraction in the free version) quite a while ago and they just keep improving it continously. The Pro version is just 100€ + VAT and you get a lesson from Chema Alonso along the way so worth considering too :).
I recently heard on the Spanish version of the PaulDotCom podcast that the tool name "FOCA" ("Seal" in Spanish) comes from the guy who first implemented the tool at informática64. His name is "Fernando Oca" and his username was logically "Foca". This led to a lot of healthy jokes at informática64 and the tool name was inevitable :).
The version used in this tutorial will be FOCA Free 2.6.1.0 (the free version has significantly less options but it is still very useful). They are going to release version 3 soon (Spanish) so I might publish another tutorial in a few months, when the tool will be significantly improved as they say.
Installation
This is a windows tool so you just, install it (typical "next next finish" install) and run it. No secrets here 🙂
Basic usage
The first step when using FOCA is to choose your search type, you can choose "site:target.com" or "site:target.com filetype:doc", etc.
In this demonstration we will use www.google.com and search for .doc documents only. Because Google is mostly a Linux/MAC shop (asfaik) this yields little results which is good for demonstration purposes:
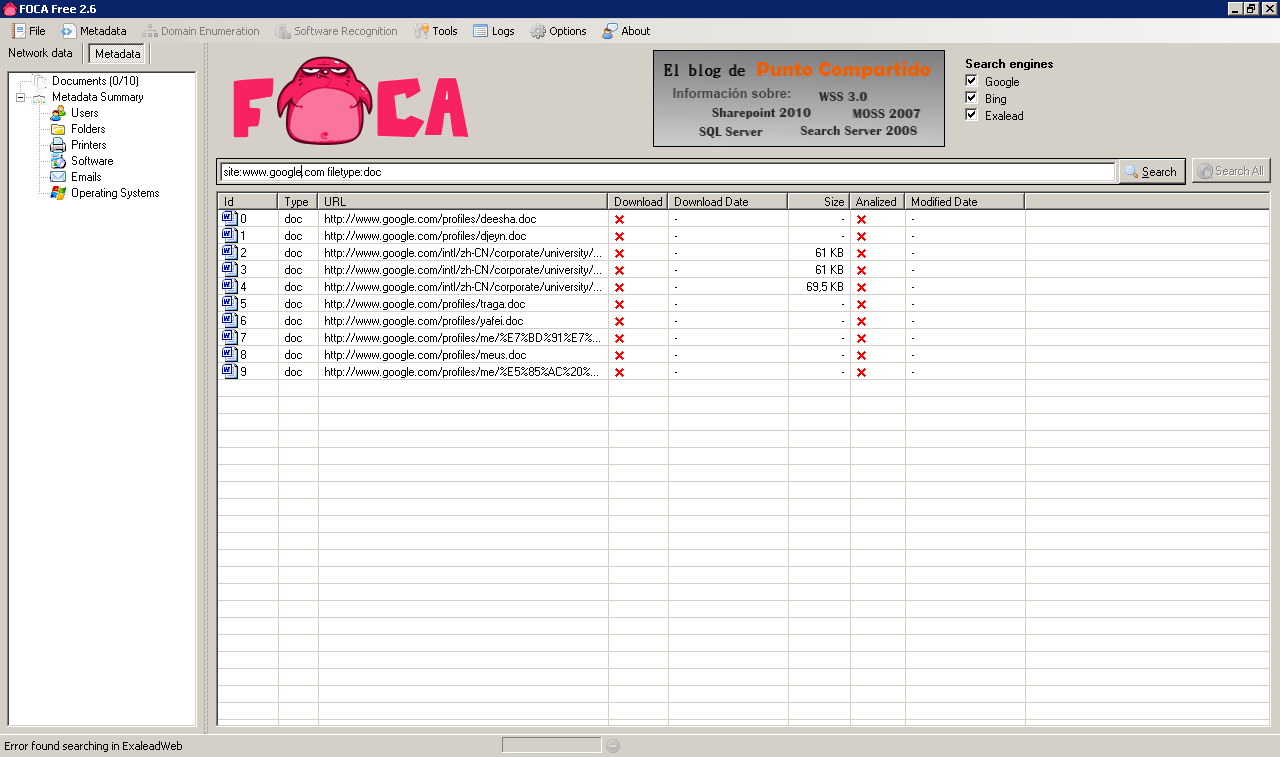
When you have a bunch of sites as I did in a recent test I like to use: site:target1.com OR site:target2.com ..... and if they are not very big do not specify a filetype: This will return everything, including web pages, which you can analyse later for HTML comments, etc too.
The next step is to download all documents, to do that just Right click / Download All:
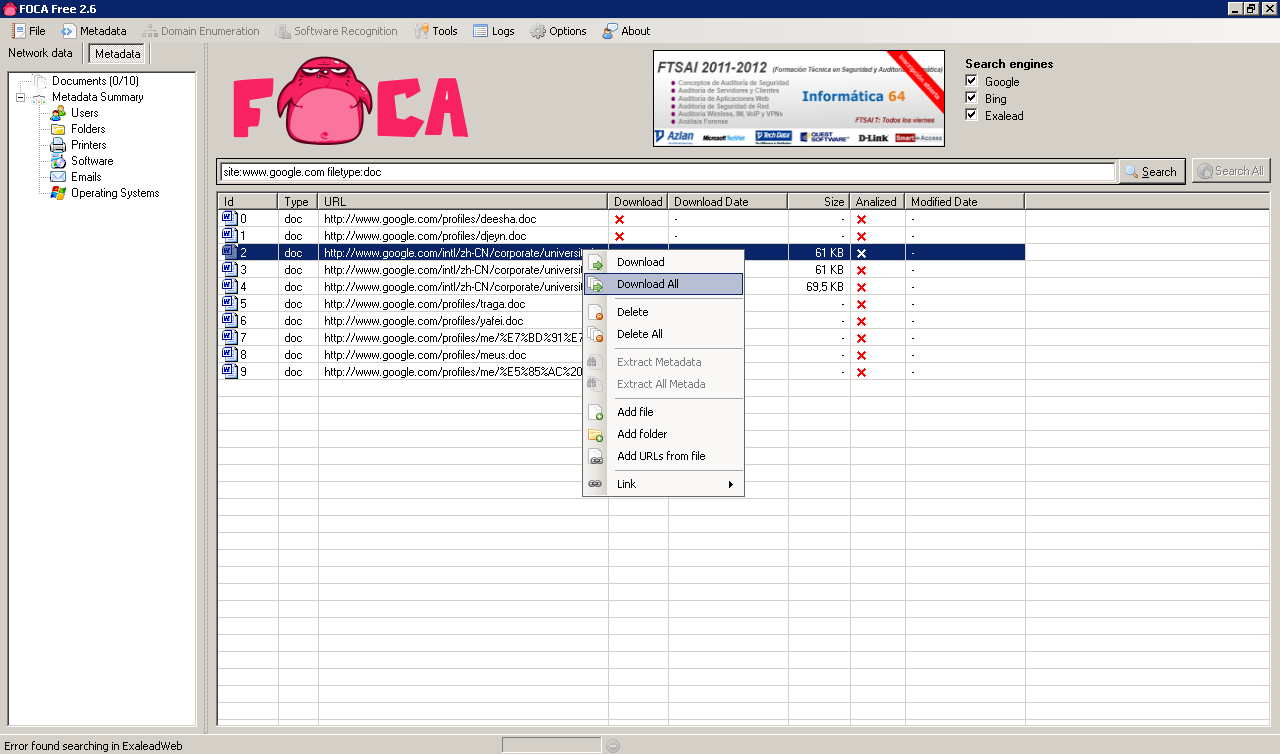
This will download all indexed files locally, after the download completes we can retrieve the metadata from the downloaded files (Metadata / Extract all documents metadata):
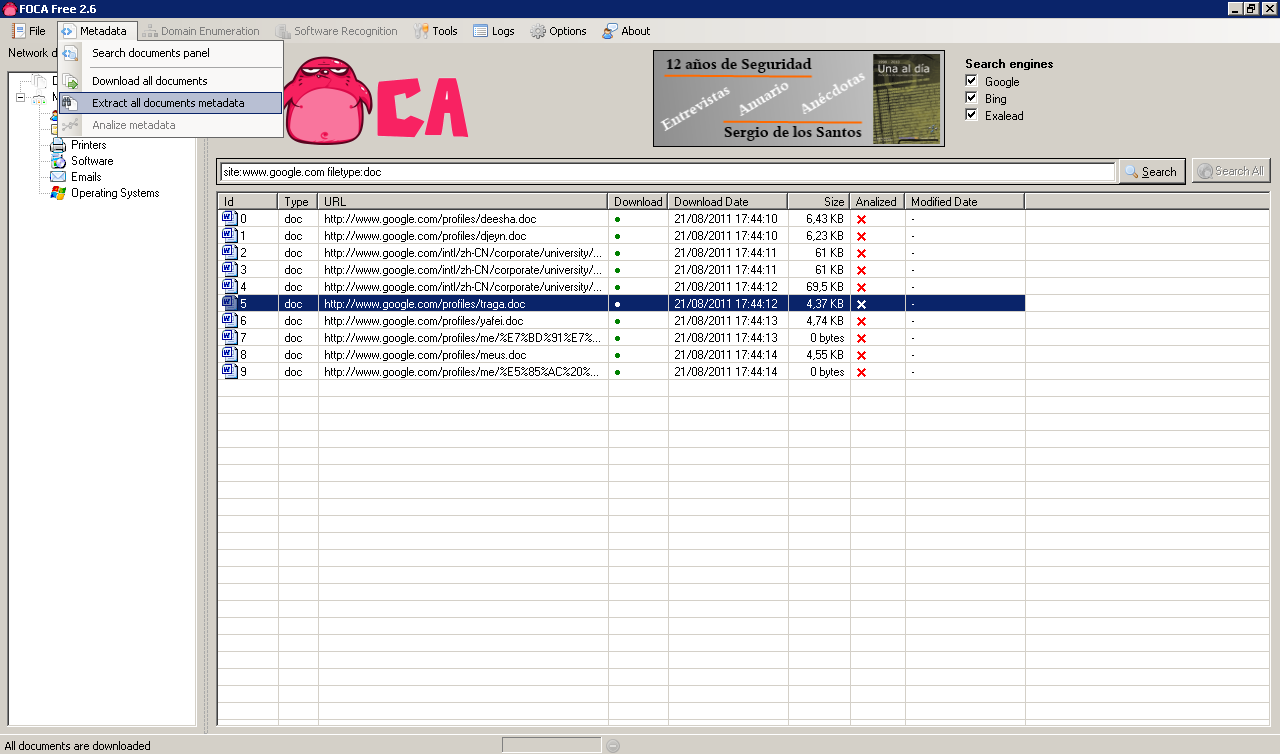
Once the metadata is extracted we can review it:
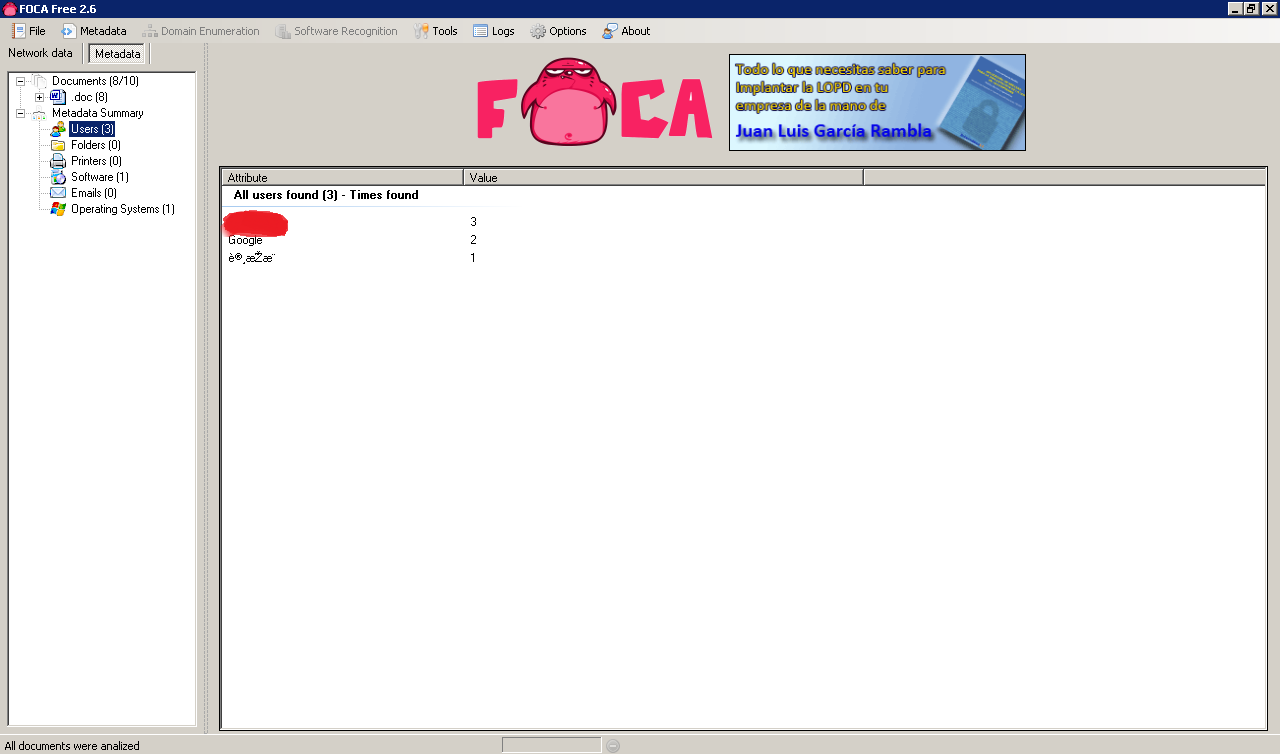
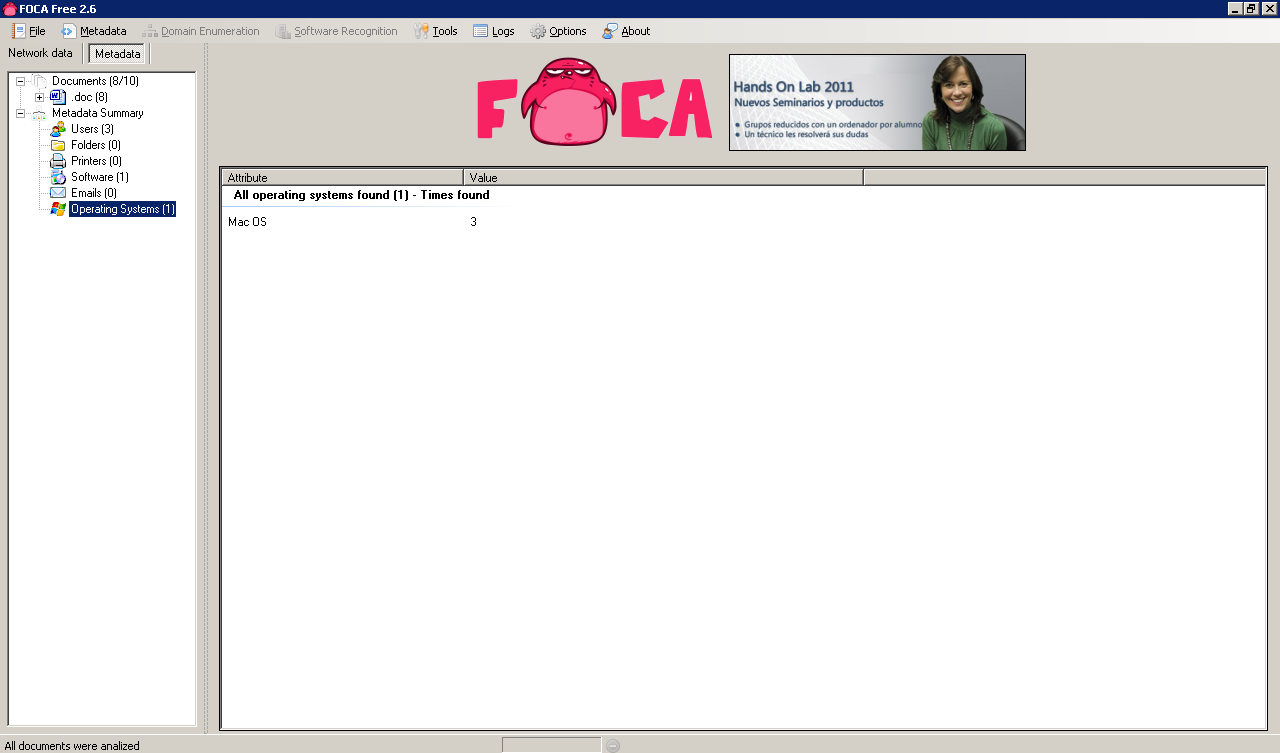
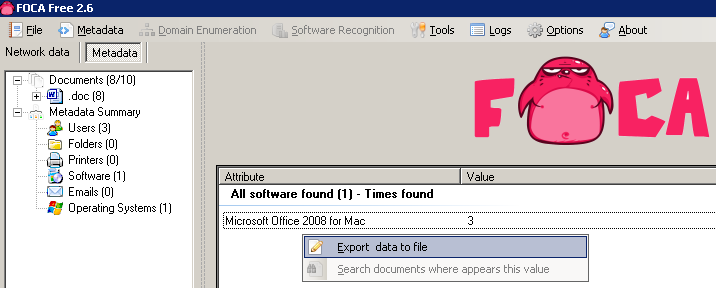
The metadata identifies 3 potential users as well as 1 software package in use and an operating system.
Apparently all 3 users are using Mac OS at Google! 🙂
We can now correlate the metadata to get a per user, printer, etc view. We can do this as follows:
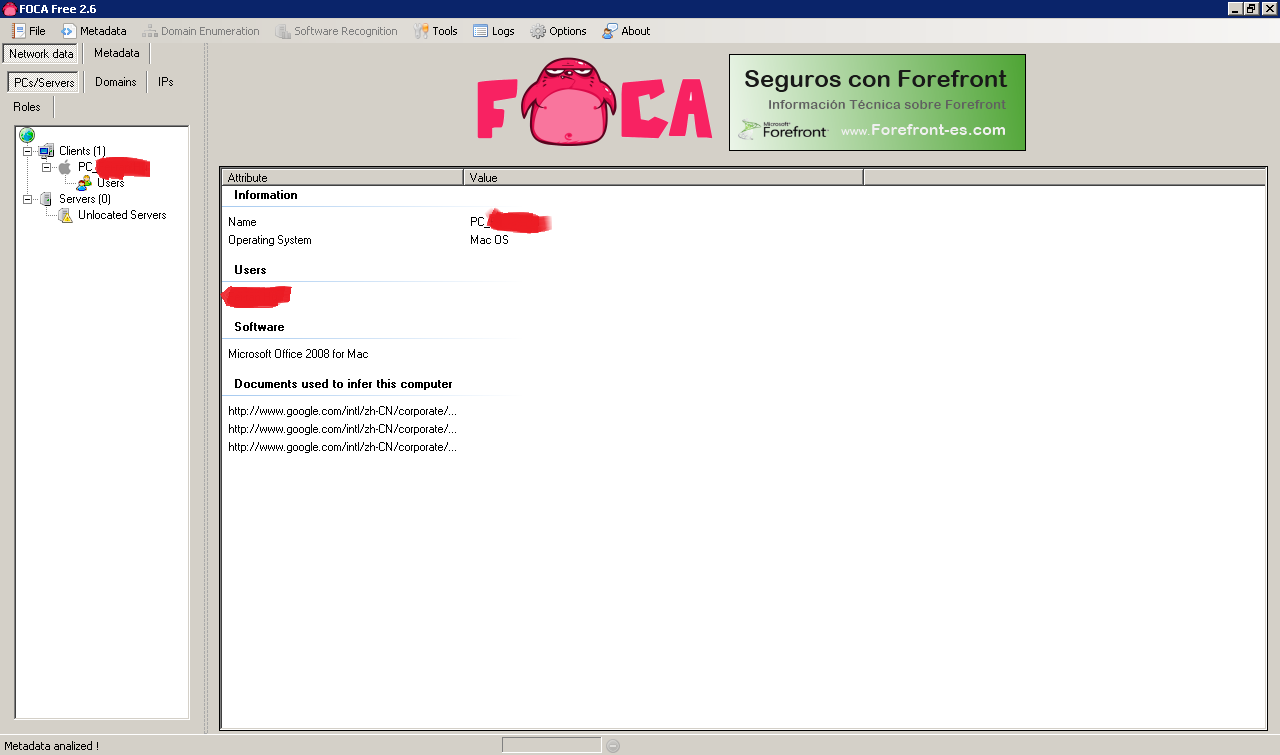
In the analysis we can see that all the metadata comes from the same user, who is using Mac OS and Microsoft Office 2008 for Mac OS. This information would be useful in a targetted client side attack because specific exploits could be searched for the versions in use by the client:
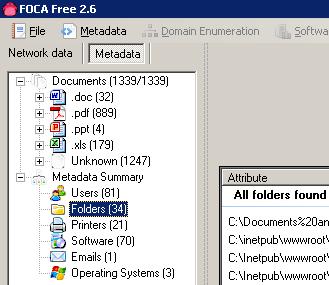
Now let's look at information from the field. What can you really find in a normal pen test?
A bunch of users, printers, folders, software and operating systems 🙂
When you look on the by user metadata analysis you can see what software version is potentially running each user and you get a nice icon to quickly identify each computer by username:
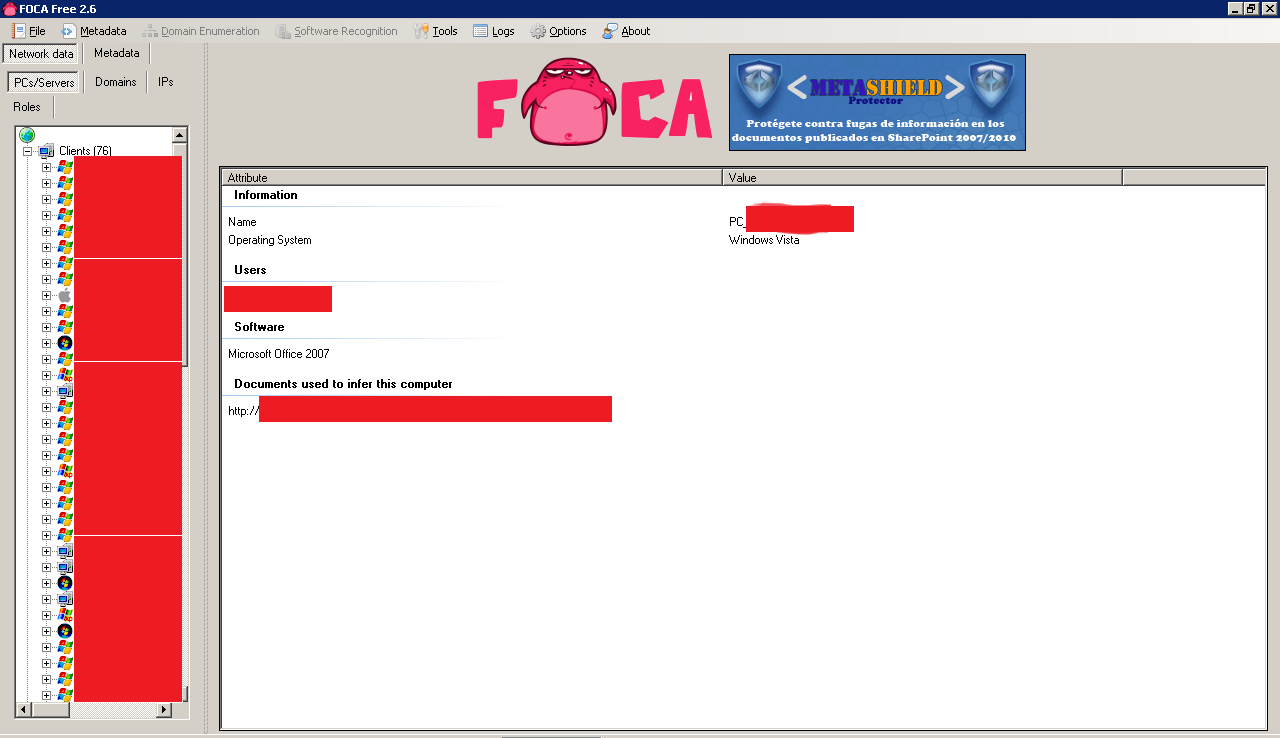
The servers and printers usually contain very interesting correlated information like for example which users had access to each printer or server.
It is a bit of a pain to extract the information out of FOCA Free (I suppose this is easier to do in the paid version :)) but you can at least browse the downloaded files and perhaps even run them through another metadata tool like the exiftool. You can extract the information of each record (one by one manually) by right clicking on it:
On a default Windows 7 Installation FOCA downloads the files on:
C:Users
You can tell apart the FOCA files from the rest quite accurately based on the download timestamp.
A minor issue, particularly when many domains are used at once is that files like index.php will be created as "index(1).php", "index(2).php", etc. Then it takes a bit of work to figure out which index.php belongs to each domain.
Better results can be achieved with a tool like wget or Httrack for website crawling and HTML comments and JavaScript code analysis.
The true power from FOCA comes from the automated "even my grandma can do it" metadata analysis, including correlation by user, server and printer.
